Introduction
I recently worked on a command line trading application (Github), optimized for low latency trading requests using websockets. It implements Deribit API, however the application uses a dependency-inversion pattern so that using another API is as simple as creating a C++ class derived from the common trading interface class.
This blog highlights the methods involved to identify high latency, bottlenecks / hot paths in the application and the requisite steps I took to optimize the code. This blog also serves as a general guide to profiling different parts of your application in C++, as well as features required for low-latency trading.
It is important to note that the code examples here refer to class deribit as a derived class from class trade_handler.trade_handler acts as an interface (abstract class).
1. CPU Optimization
Identifying Initial Bottlenecks
Step 1
When profiling the application for the first time with gprof the following results were established. The bottleneck identified is deribit::auth. The function waits till the API returns an access token which is necessary for confirming authentication and may be required for private calls to the API. According to the following results, we must optimize the code which waits for the access token.
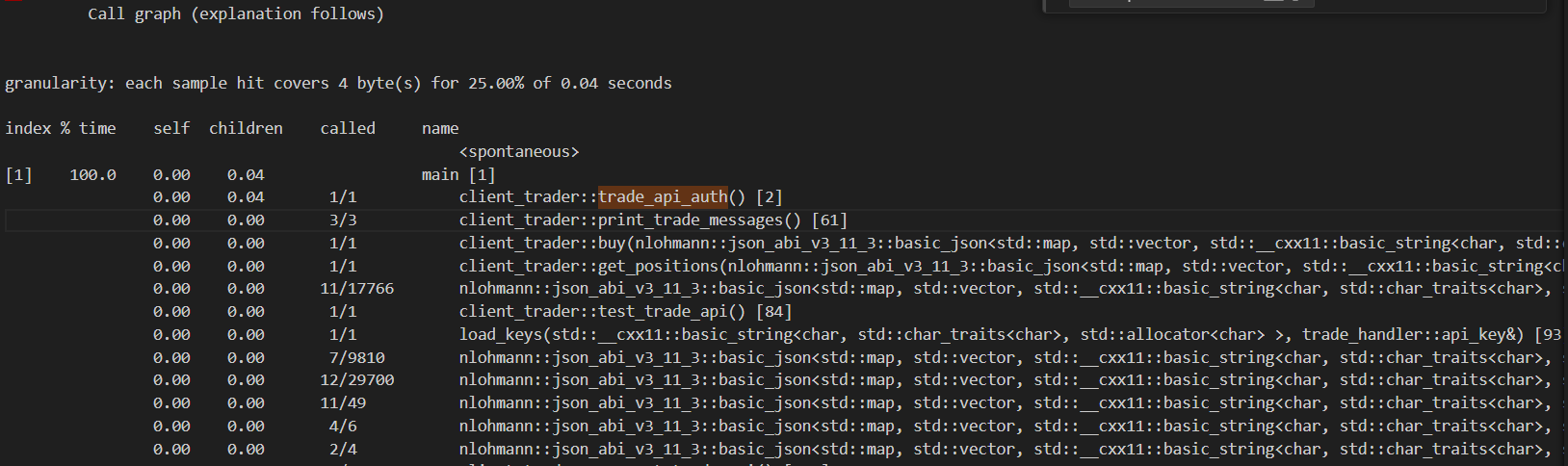

The line below refers to the function json::parse() from the nlohmann_json library.
0.00 0.00 13/15 nlohmann::json_abi_v3_11_3::basic_json<...>, ... nlohmann::json_abi_v3_11_3::adl_serializer [1014]
The code for deribit::auth() before optimizations involved checking and parsing latest messages every iteration.
if(!result.ec) {
using namespace std::chrono_literals;
// wait for response
json json_response;
while(true) {
auto msg = m_endpoint->get_latest_message(m_con_id);
if(!msg || msg->length() <= WS_MSG_TYPE_LEN) continue;
json_response = json::parse(msg->substr(WS_MSG_TYPE_LEN));
if(json_response.contains("result") && json_response["result"].contains("access_token")) {
m_access_token = json_response["result"]["access_token"];
break;
}
}
APP_LOG(log_flags::trade_handler, "(deribit) access token: " << m_access_token);
}
We can fix this by parsing the message only if a new message arrives. Using the statements
auto tmp = m_endpoint->get_latest_message(m_con_id);
if(tmp == msg) continue; // check if new message has arrived
Step 2
After fixing continuous parsing of messages as json, we profile the application again.

The function performs slow due to large number of calls to get_latest_message. We can reduce the calls to get_latest_message by reducing the polling, by adding a thread delay.
auto thread_sleep_time = 100ms;
while(true) {
// add a thread sleep to avoid excessively polling get_latest_message
std::this_thread::sleep_for(thread_sleep_time);
We have successfully reduced the number of calls to get_latest_message from ~420,000 to 3 calls. Additionally the time spent on the function deribit::auth() reduced from 0.04s to 0.00s (below gprof’s measurement threshold).

Additionally the final implementation of deribit::auth() involves a timeout which exits the function if the access token is not retrieved within a fixed amount of time.
The final function definition is available in api/deribit.h.
Profiling with callgrind
Since gprof does not give high frequency sampling, we will use the callgrind tool and analyze it using KCachegrind.
Step 1
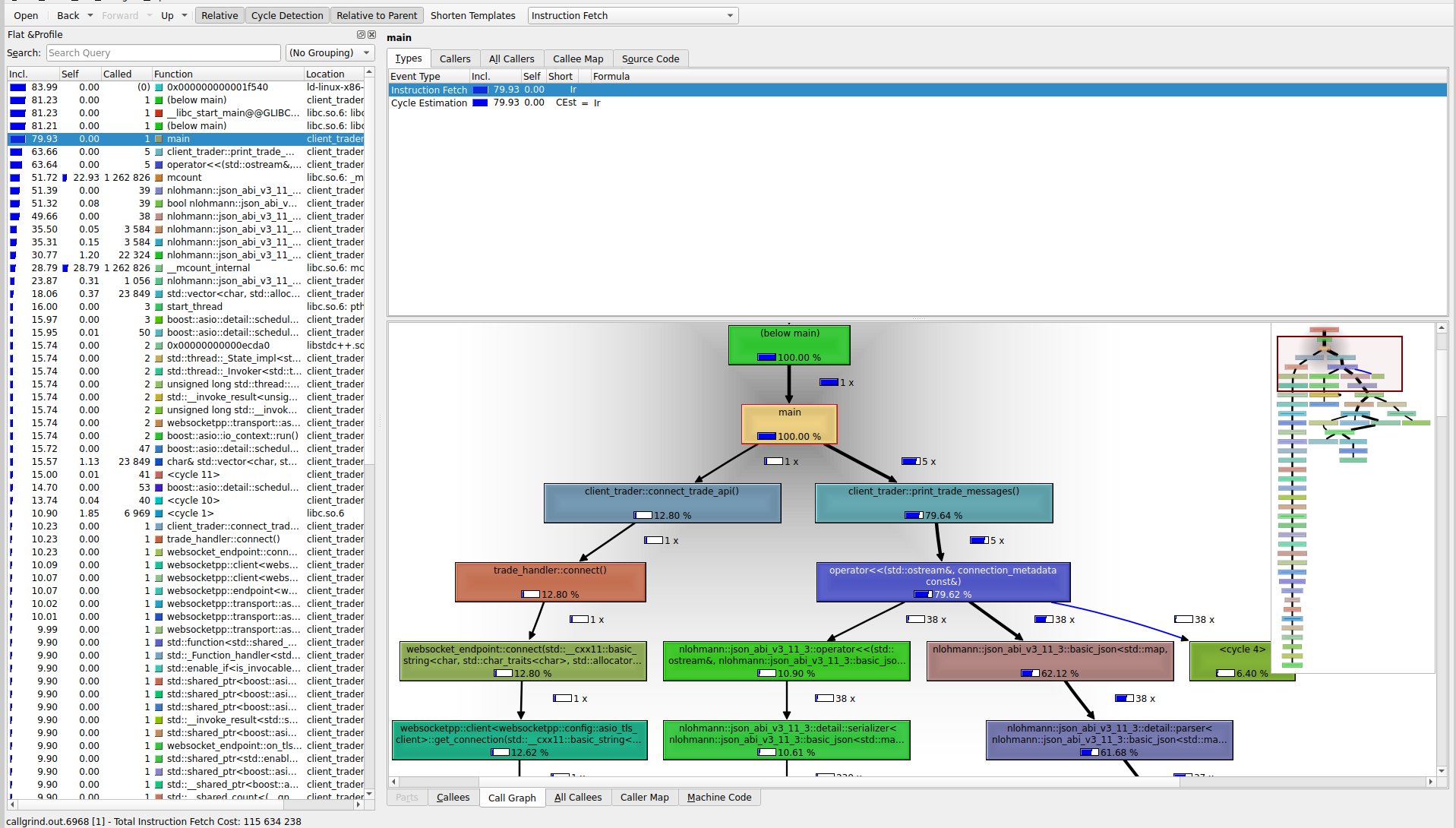
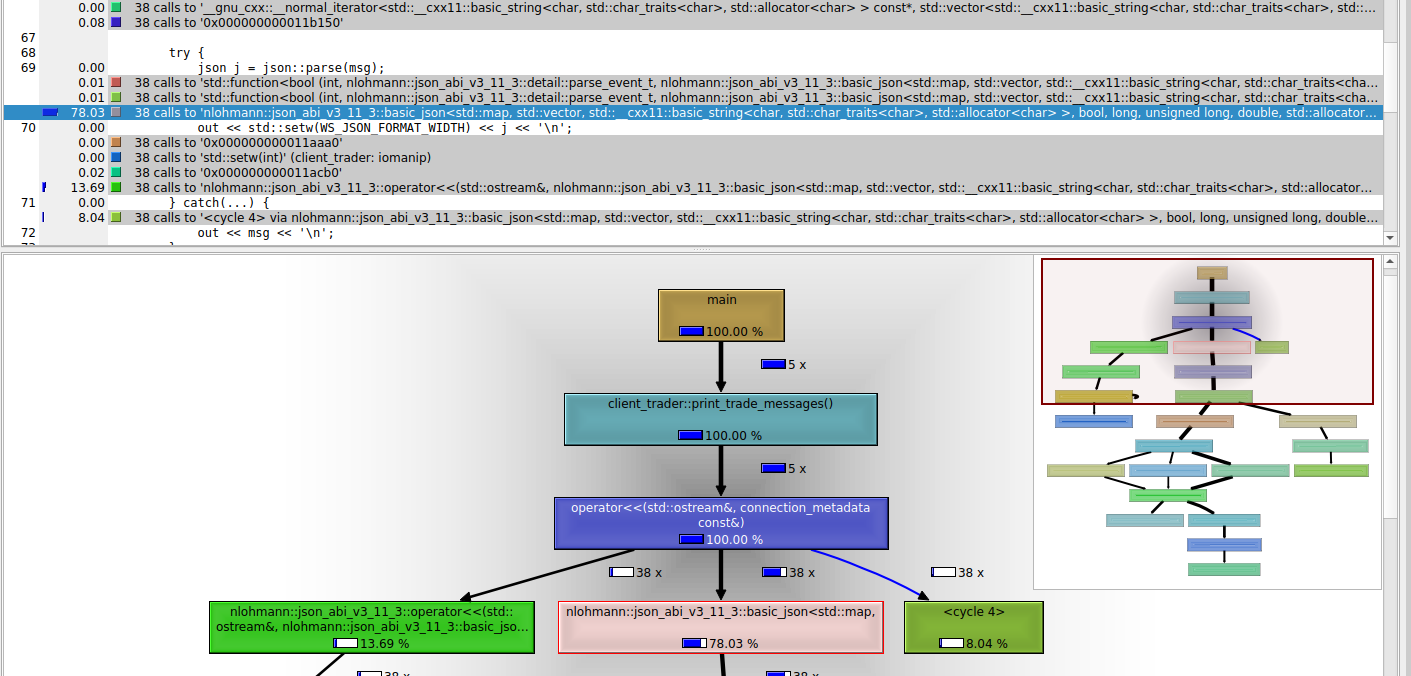
The profile shows a graph of the function calls and the percentage of time on each call. According to the first image, we see callgrind recognizes print_trade_messages as a major bottleneck with 79% of the time spent on it. The second image highlights that majority of the time is spent in “pretty-printing” the json messages using nlohmann json library. This method is invoked when we run the command deribit_show.
The lines of code responsible are shown in the second image.
Step 2
To identify other major hot paths, we should temporarily disable pretty printing of json messages in the network communication.
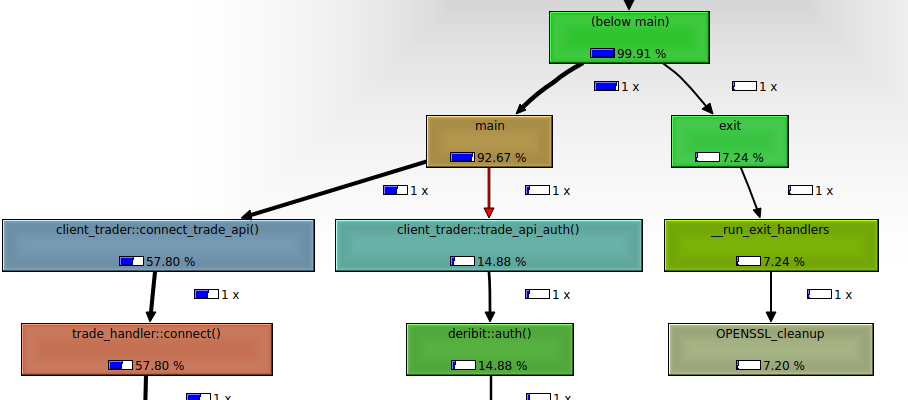
Now, we rerun the application and invoke all the possible deribit commands in our application. The below graph and show that the trading methods such as deribit_buy, deribit_positions etc. have a much lower execution time than the connect and auth methods.
Call graph:
Flat profile:
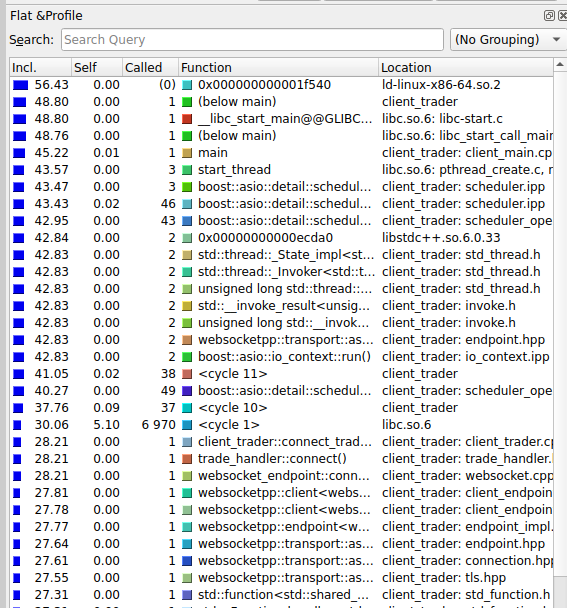
- We have already optimized the
deribit::auth, however it has a relatively higher execution time since it waits for the API to return the access token. - Our
client_trader::connectmethod directly calls the underlying connect method fromwebsocketpplibrary.
Since, these methods are only invoked only once on application start a relatively higher execution time may be acceptable according to requirements.
Analysis of buy function
We will focus on the deribit::buy function since it sends the largest request from all of our deribit commands, making it suitable for analysis.
We can confirm that requests with large request body such as private/buy do not cause bottlenecks and work at low latency. the self time for deribit::buy is much lower compared to the auth and connect methods. The highlighted blue function in the below image refers to the deribit buy function.
Note: the self and include times mentioned are in relative mode, hence they refer to timing relative to other methods mentioned.
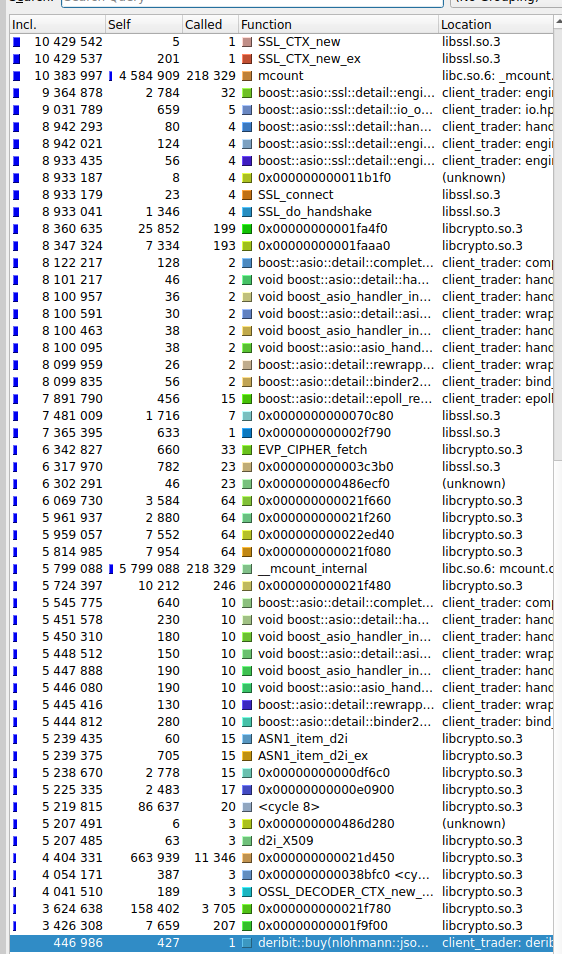
Step 1
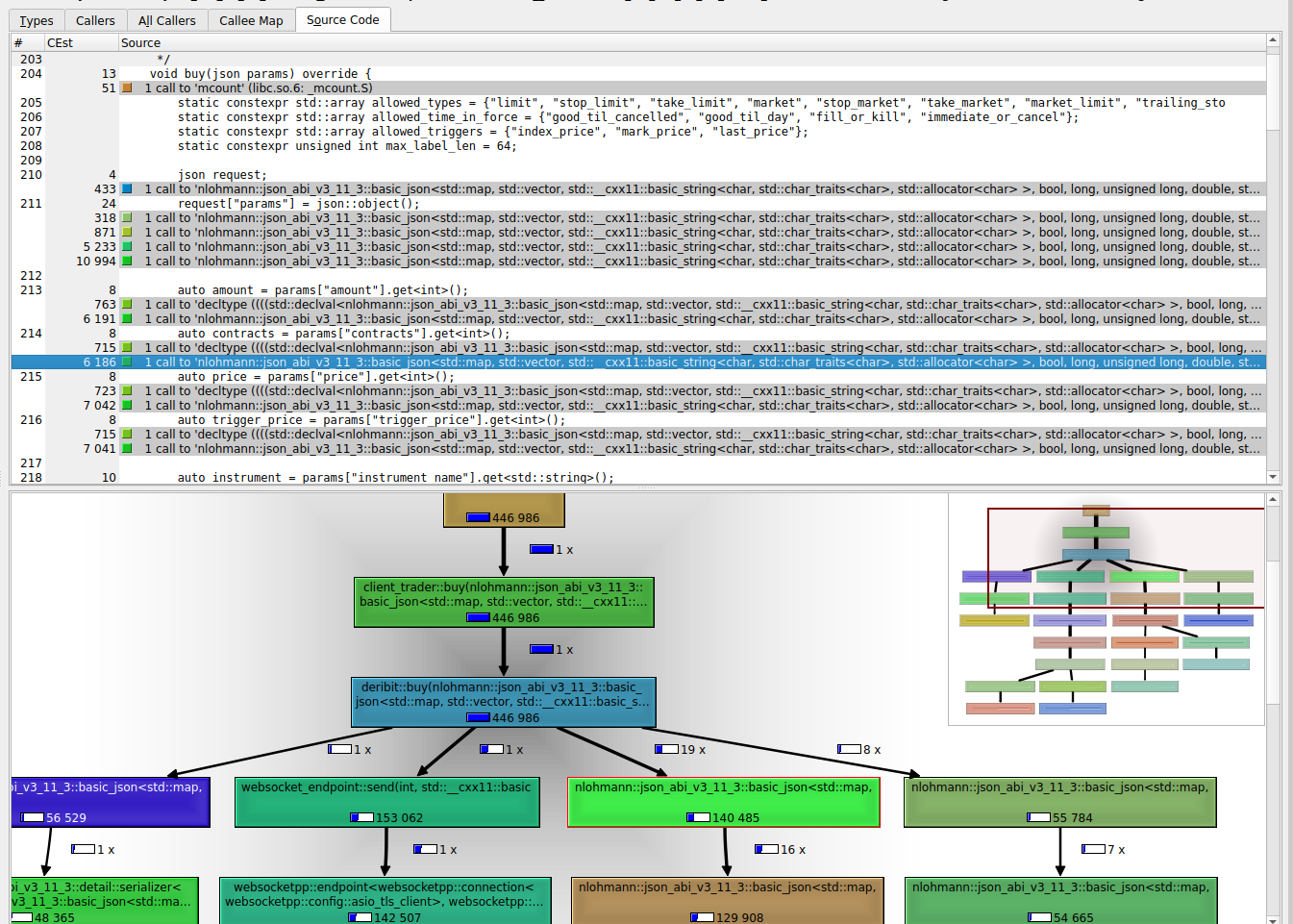
The methods nlohmann::json_abi_...::basic_json refer directly or indirectly to the conversion of JSON data to C++ data types / strings.
The trade_handler buy method is defined to take a single object as the set of parameters which the function definition will access.
- This also ensures that a different API can use seperate parameters as the arguments passed to the function.
The original code used a common json object for parameters:
void trade_handler::buy(json params);
Original code:
void deribit::buy(json params) {
json request;
auto instrument = params["instrument_name"].get<std::string>();
if(instrument.empty()) {
// verify parameters ...
}
request["params"] = json::object();
request["params"]["instrument_name"] = instrument;
}
Since, the conversion of data types using .get() is costly, we can optimize the performance by using a common struct for the parameters
struct buy_params {
float amount;
float contracts;
float price;
float trigger_price;
std::string instrument;
std::string type;
std::string label;
std::string time_in_force;
std::string trigger;
// for edit and cancel orders
std::string order_id
};
The optimized code below does not require any conversion of data types while not losing the abstraction layer of trade_handler.
void deribit::buy(trade_handler::buy_params params) {
if(params.instrument.empty()) {
// verify parameters ...
}
json request;
request["params"] = json::object();
request["params"]["instrument_name"] = params.instrument;
}
Result
Before:


After:


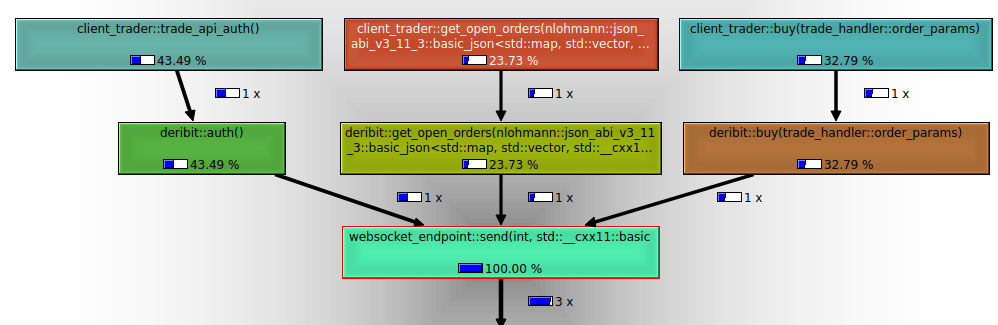
Analysis of send requests
The following graph indicates the amount of time spent on send requests from the application. As we expect deribit::buy takes a longer amount of time than requests such as deribit::get_open_orders. The detailed analysis of timings can be seen in the benchmark section.
2. Memory Optimization
Memory Profiling
First Run
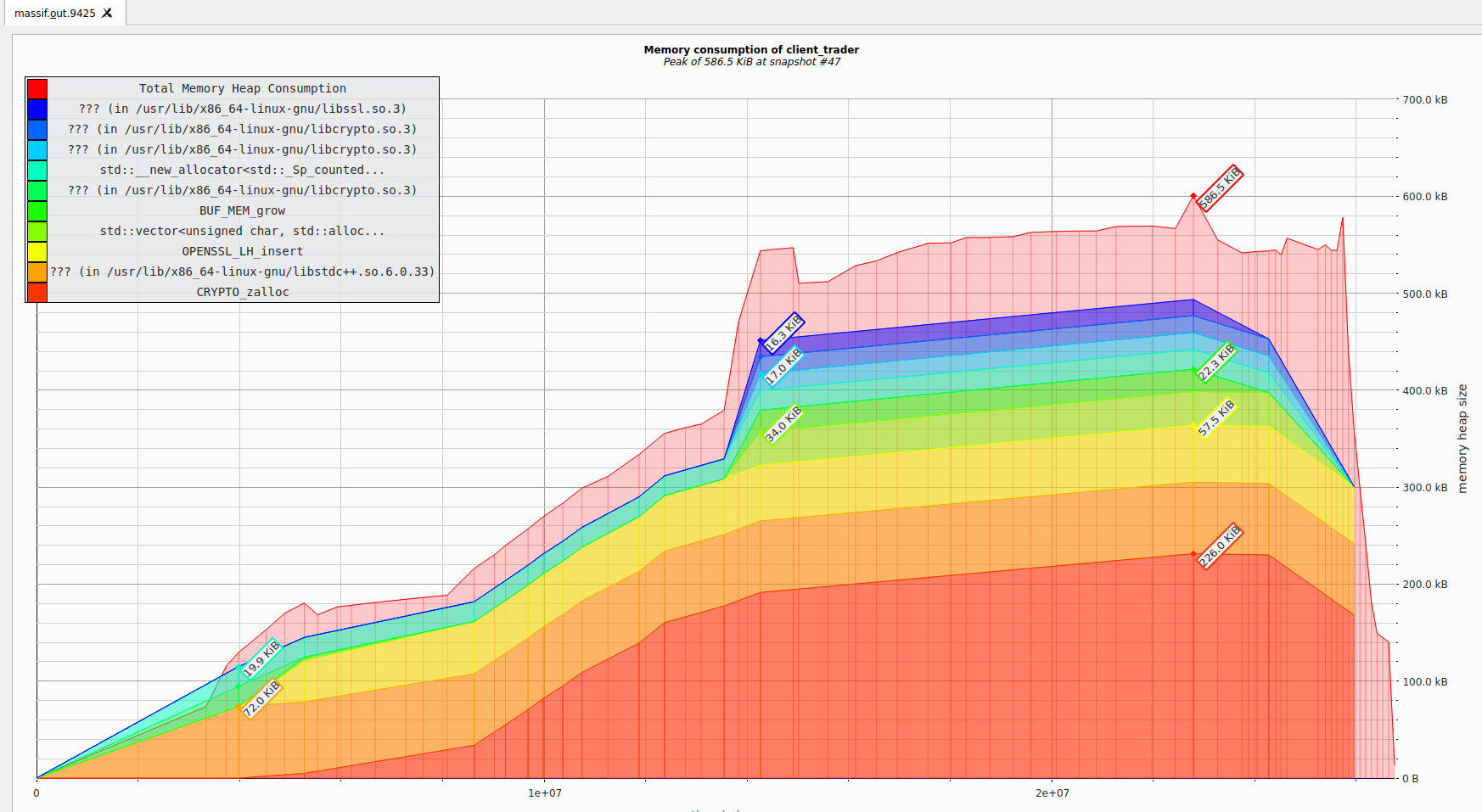
The heap memory profiling was done using the tool massif and visualized using massif-visualizer program.
valgrind --tool=massif client_trader
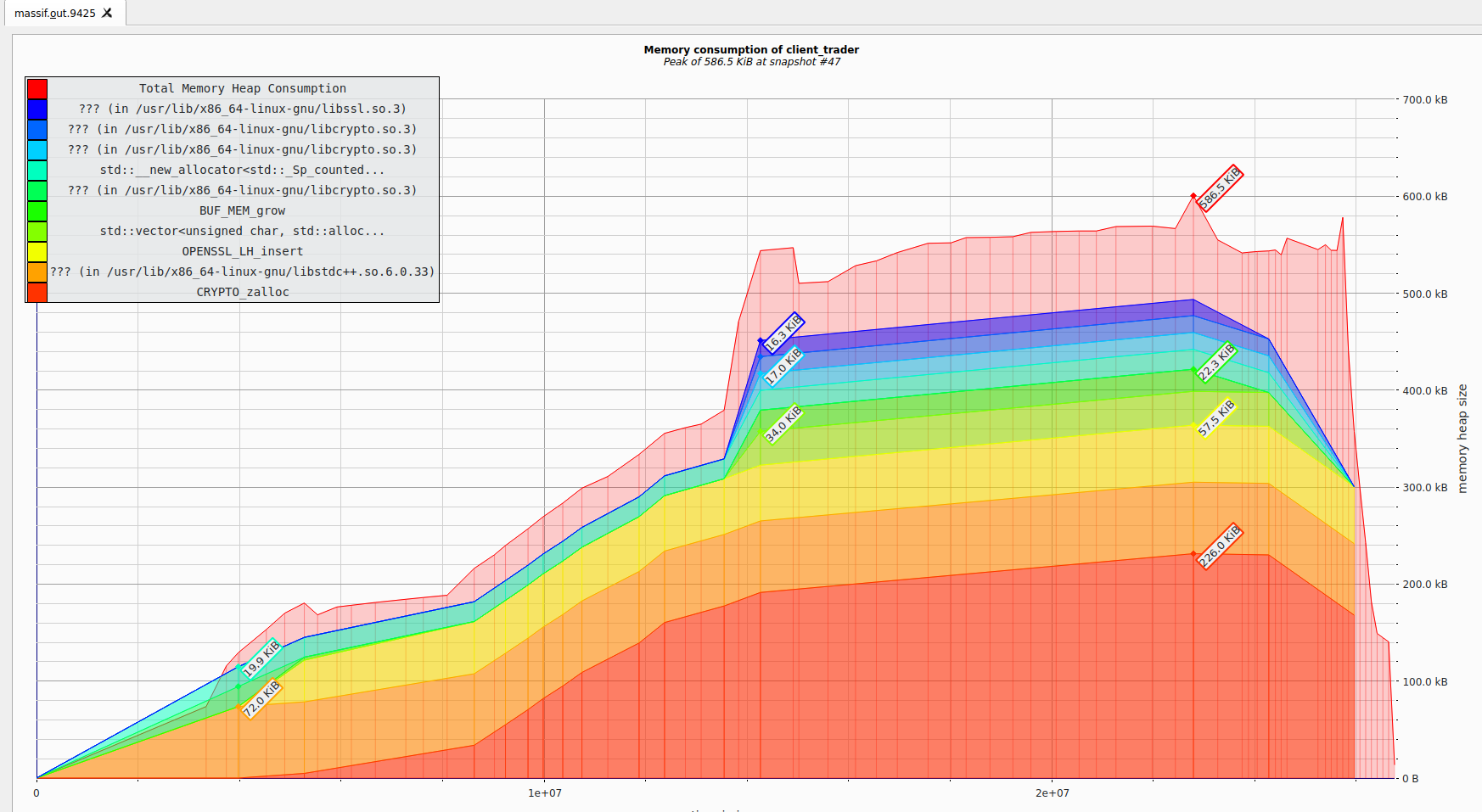
The peak heap memory usage is 586kb. The snapshot of peak usage is as follows:
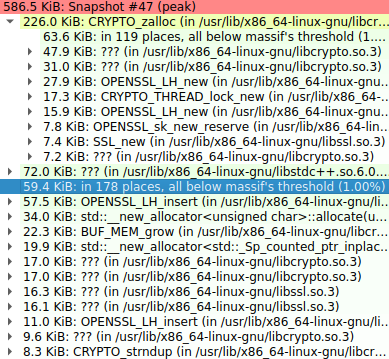
The allocators used were:
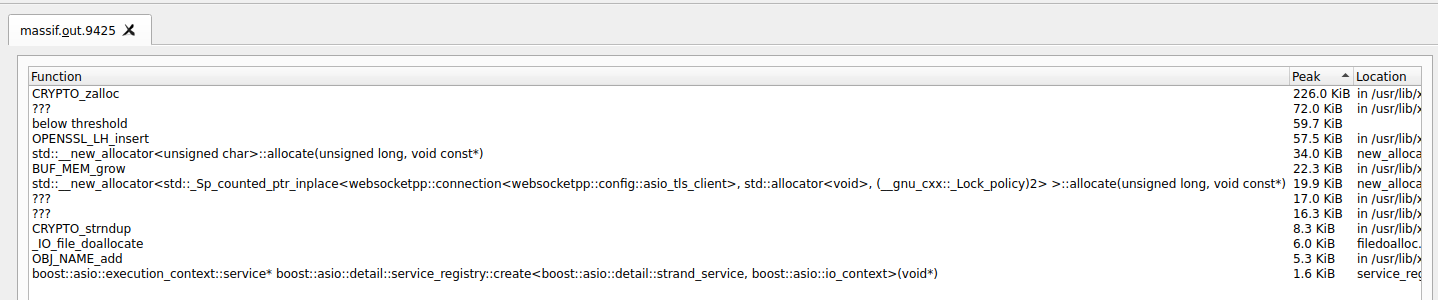
This shows us that we did not do any significant heap allocation and majority of it was done by the websocketspp library as shown in the graph legend.
Second Run
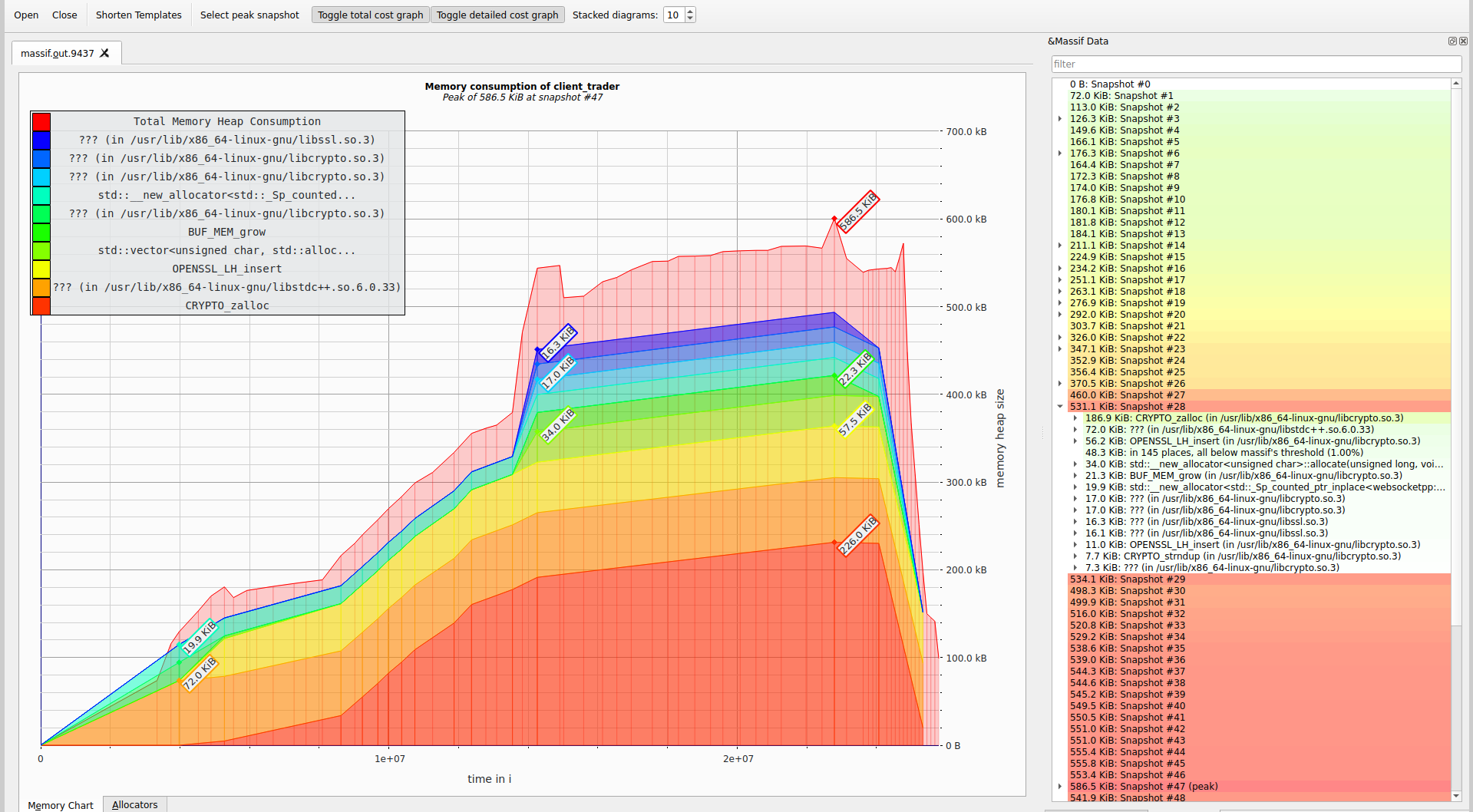
A second profile of the application showed a similar graph for heap memory allocation.
Analysis of Memory Leaks
We can detect memory leaks in the application using valgrind.
valgrind --leak-check=full -v ./client_trader
==9504== ERROR SUMMARY: 2 errors from 2 contexts (suppressed: 0 from 0)
==9504==
==9504== 1 errors in context 1 of 2:
==9504== Mismatched new/delete size value: 120
==9504== at 0x484A5B9: operator delete(void*, unsigned long) (in /usr/libexec/valgrind/vgpreload_memcheck-amd64-linux.so)
==9504== by 0x11DF40: main (client_main.cpp:250)
==9504== Address 0x53e5200 is 0 bytes inside a block of size 152 alloc'd
==9504== at 0x4846FA3: operator new(unsigned long) (in /usr/libexec/valgrind/vgpreload_memcheck-amd64-linux.so)
==9504== by 0x11C800: main (client_main.cpp:44)
==9504==
==9504== ERROR SUMMARY: 2 errors from 2 contexts (suppressed: 0 from 0)
These memory leak errors refer to the lines:
// client_main.cpp
44: trade_handler* deribit_handler = new deribit{};
250: delete deribit_handler;
This is a subtle memory leak caused in our application due to varying size of base and derived classes. Since trade_handler and deribit_handler have a different size we cannot use the base class pointer to delete the allocation.
This can be fixed by managing the derived class’s memory using a smart pointer. Later we extract the raw pointer and interface it through trade_handler*.
std::unique_ptr<deribit> deribit_uptr = std::make_unique<deribit>();
trade_handler* deribit_handler = deribit_uptr.get();
Result:
==10118== HEAP SUMMARY:
==10118== in use at exit: 0 bytes in 0 blocks
==10118== total heap usage: 14,360 allocs, 14,360 frees, 1,903,315 bytes allocated
==10118==
==10118== All heap blocks were freed -- no leaks are possible
==10118==
==10118== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
However, we should still define a virtual destructor for trade_handler as we may use raw pointer using new to instantiate a deribit type object.
virtual ~trade_handler() {}
Reference: https://stackoverflow.com/questions/461203/when-to-use-virtual-destructors
3. Code Optimization Methods
Thread Management
The application uses 2 threads, one main thread and when for the running the websocket endpoint.
// run endpoint on seperate thread
m_thread = websocketpp::lib::make_shared<websocketpp::lib::thread>(&client::run, &m_endpoint);
- This ensures that other computations or user interaction can occur while network requests are processed in the background
The thread is gracefully joined to the main thread when our websocket_endpoint class (websocket/websocket.cpp) goes out of scope. The thread is joined when all connections are closed in the destructor.
websocket_endpoint::~websocket_endpoint() {
// close connections
for (con_list::const_iterator it = m_connection_list.begin(); it != m_connection_list.end(); ++it) {
// ...
m_endpoint.close(it->second->get_hdl(), websocketpp::close::status::going_away, "", ec);
}
// wait till thread is complete
m_thread->join();
}
Network Optimizations
-
The application uses TLS configuration for secure communication with the server
-
A map data structure is used to query a list of active connections quickly.
typedef std::map<con_id_type, connection_metadata::ptr> con_list;
con_list m_connection_list;
-
The code for
websocket_endpointis exception safe and returns error codes instead, making it perform at low latency and avoid uncaught exceptions / memory leaks. -
The configuration of websocketspp client enables concurrency by default. We can additionally enable
permessage_deflatefor large requests.
typedef websocketpp::client<websocketpp::config::asio_tls_client> client;
4. Latency Benchmarking
The latency benchmarking is done using a special class defined for benchmarking.
class benchmark {
public:
benchmark(std::string lab): label{lab} {}
void reset(std::string lab = "");
void start();
void end();
private:
std::string label;
bool started = false;
std::chrono::time_point<std::chrono::high_resolution_clock> start_time;
std::chrono::time_point<std::chrono::high_resolution_clock> end_time;
};
In order to support end to end benchmarking (as well as across threads), we have defined a benchmark g_benchmark {"g_benchmark"}; in client_main.cpp which can be accessed by other source files using extern.
For example:
// client_main.cpp
g_benchmark.reset("e2e_" + order_type + "_order_" + "benchmark");
g_benchmark.start();
if(order_type == "buy")
trader.buy(params);
// websocket.cpp
websocket_endpoint::send_result websocket_endpoint::send(con_id_type id, std::string message) {
// benchmark send request
benchmark send_benchmark {"send_request_benchmark"};
send_benchmark.start();
// ...
// end send request benchmark
send_benchmark.end();
// end global benchmark
g_benchmark.end();
return result;
}
This gives the following benchmarking results.
Created connection with id 0
Enter Command: deribit_auth
[ 7792ms] Started benchmark: e2e_auth_benchmark
[ 7792ms] Started benchmark: send_request_benchmark
[ 7792ms] Benchmark: send_request_benchmark, took 69 us
[ 7792ms] Benchmark: e2e_auth_benchmark, took 131 us
[ 8001ms] trade_handler: (deribit) access token: ...
Enter Command: deribit_buy
Enter buy order details
Instrument: BTC-PERPETUAL
Amount: 50
Contracts:
Price: 50
Type:
Label:
Time in force:
Trigger:
Trigger Price:
[ 23847ms] Started benchmark: e2e_buy_order_benchmark
[ 23847ms] trade_handler: (deribit) Buy order request sent. Check details
[ 23847ms] Started benchmark: send_request_benchmark
[ 23847ms] Benchmark: send_request_benchmark, took 48 us
[ 23847ms] Benchmark: e2e_buy_order_benchmark, took 220 us
Enter Command: deribit_show
e2e_buy_order_benchmark refers to the end-to-end trading latency, while send_request_benchmark only refers to the time taken to propagate the message.
Additional benchmarking showed that send requests were always < 100us, and end-to-end buy trading loop was on the order of ~150-200us.